
Navigating the AI Observability Maze: Azure ML vs. AWS SageMaker vs. GCP Vertex AI
Deploying an ML model is just the beginning of the journey. Like any sophisticated engine, AI models require constant vigilance to ensure they’re performing optimally, fairly, and reliably. Without it, even the most brilliant model can silently degrade, leading to flawed decisions and eroding trust. This is where AI model monitoring, a cornerstone of mature Machine Learning Operations (MLOps), steps in.
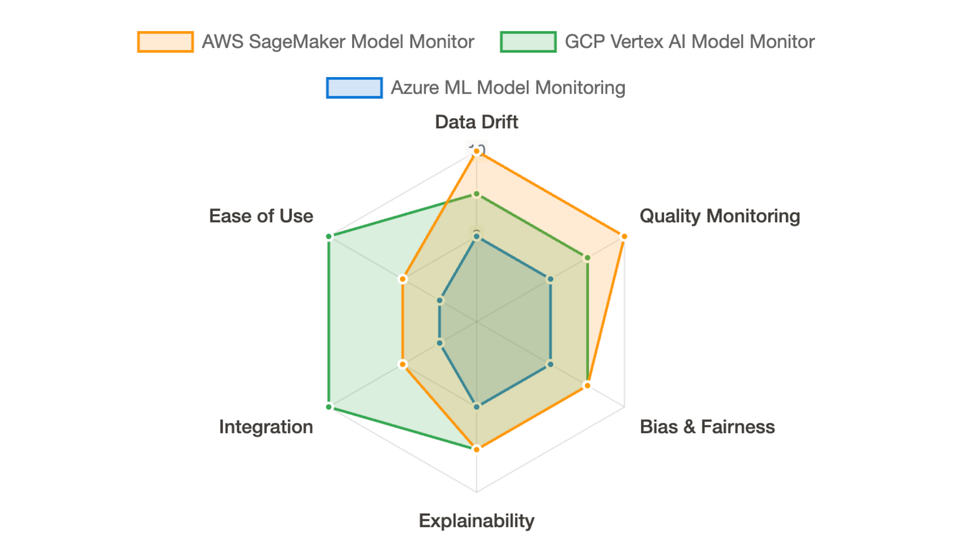
In this post, we'll dive into the AI observability offerings of the three major cloud technology providers: Azure Machine Learning (Azure ML), Amazon Web Services (AWS) SageMaker Model Monitor, and Google Cloud Platform (GCP) Vertex AI Model Monitoring. We'll explore how each platform helps you keep a watchful eye on your deployed models, ensuring they continue to deliver value long after they've left the development nest.
Why AI Model Monitoring is No Longer a Luxury, But a Necessity
Several factors make AI model monitoring indispensable:
The Silent Threat of Drift
The world isn't static, and neither is your data.
- Data drift occurs when the statistical properties of the input data your model sees in production change compared to the data it was trained on.Think of a retail model trained pre-pandemic suddenly facing a world of online shopping surges and supply chain disruptions.
- Concept drift is even more dangerous; it's when the underlying relationship between your input features and what you're trying to predict changes.For example, what constituted a "risky" loan application might change dramatically with new economic policies. Both types of drift can silently erode your model's accuracy if left unchecked.
The Responsible AI Imperative
AI models can inadvertently learn and amplify biases present in their training data, leading to unfair or discriminatory outcomes.Monitoring for bias and fairness isn't just ethical; it's increasingly a regulatory requirement.
Demystifying the Black Box
Understanding why a model makes a particular prediction (explainability) is crucial for trust, debugging, and compliance.Monitoring changes in feature importance (feature attribution drift) can signal that a model is starting to behave unexpectedly.
Ensuring Peak Performance
Beyond drift and bias, you need to continuously track core model quality metrics like accuracy, precision, recall, or F1-score, as well as operational metrics like latency and error rates, to ensure your model is delivering on its promise.