
GPUs vs. TPUs: Decoding the Powerhouses of AI
The artificial intelligence revolution is upon us, transforming industries and reshaping our daily lives. At the heart of this transformation lies an insatiable demand for computational power. Training sophisticated deep learning models, especially the colossal Large Language Models (LLMs) that captivate us with their human-like text generation, or the intricate Convolutional Neural Networks (CNNs) that enable machines to "see," requires processing capabilities that dwarf traditional computing. This computational hunger has spurred the development of specialized hardware accelerators, with Graphics Processing Units (GPUs) and Tensor Processing Units (TPUs) emerging as the undisputed champions in this high-stakes arena.
But when faced with the choice between these two options, how do you decide which one is the right fit for your specific deep learning endeavors? This blog post aims to demystify GPUs and TPUs, diving deep into their architectures, how they handle the critical matrix calculations that underpin AI, their performance characteristics across various workloads, and the software ecosystems that bring them to life. By the end, you'll have a clearer understanding to help you navigate this decision.
The Architects of Acceleration
Understanding GPU and TPU Designs
To appreciate their differences, we first need to look under the hood.
GPUs: From Pixels to AI Dominance
Graphics Processing Units, as their name suggests, were originally conceived to render the complex visuals of video games and professional graphics applications.This task is inherently parallel, requiring the same operations to be performed on millions of pixels simultaneously. This parallel processing prowess, particularly the Single Instruction, Multiple Data (SIMD) paradigm, proved remarkably adaptable to the mathematical demands of scientific computing and, eventually, deep learning.
NVIDIA, a name now synonymous with AI hardware, played a pivotal role in this transition with the introduction of its Compute Unified Device Architecture (CUDA) in 2007.CUDA provided a programming model that unlocked the massive parallel processing capabilities of NVIDIA GPUs for a broader range of applications, catapulting them into the forefront of AI research and development.
Core Components of AI-focused GPUs
- CUDA Cores: These are the fundamental, general-purpose processing units within NVIDIA GPUs.Organized into Streaming Multiprocessors (SMs), thousands of these cores work in concert to execute a vast number of floating-point and integer operations in parallel, forming the bedrock of the GPU's computational engine.
- Tensor Cores: A game-changing innovation, first appearing in NVIDIA's Volta architecture, Tensor Cores are specialized hardware units meticulously designed to accelerate matrix multiplication and accumulation (MMA) operations.These operations are the computational kernel of most deep learning workloads, often consuming the lion's share of processing time.Tensor Cores achieve significant speedups by performing mixed-precision calculations (e.g., multiplying 16-bit floating-point numbers and accumulating the results in 32-bit precision) with high efficiency.Successive generations have expanded support to a wide array of precisions, including TF32, BF16, FP16, INT8, and even newer formats like FP8, FP6, and FP4 for extreme performance.
- Memory Hierarchy (VRAM, HBM, Caches): Deep learning is incredibly data-hungry. To keep the thousands of cores fed, GPUs feature a sophisticated memory hierarchy.This includes high-capacity, high-bandwidth on-board Video RAM (VRAM) – often using technologies like GDDR6X or, for high-end accelerators, High Bandwidth Memory (HBM2e, HBM3) – along with multi-level caches (L1/L2).Efficient memory access and high bandwidth are critical to prevent the processing units from stalling.
TPUs: Google's Custom-Built AI Engines
Tensor Processing Units represent Google's strategic foray into creating hardware explicitly optimized for the computational demands of machine learning, particularly neural networks.Unlike GPUs, which evolved into AI powerhouses, TPUs were conceived from day one as Application-Specific Integrated Circuits (ASICs) for AI.
This domain-specific design allows TPUs to achieve remarkable performance and power efficiency for their target computations.The first-generation TPUs, introduced in 2015, focused on accelerating inference for Google's services, while subsequent generations expanded capabilities to include model training and increasingly sophisticated distributed computing features.
Core components of TPUs
- Systolic Arrays & Matrix Multiply Units (MXUs): The computational heart of a TPU is its Matrix Multiply Unit (MXU), which is built around a systolic array.A systolic array is a large, two-dimensional grid of simple processing elements (Multiply-Accumulate units, or MACs).Data, in the form of weights and input activations, "flows" rhythmically through this array in a pipelined manner.Weights are typically pre-loaded into the MACs, and as input activations stream through, multiplications and accumulations occur in parallel across the entire array.This architecture enables massive data reuse and significantly reduces memory access during computation, boosting efficiency.
- Memory System (HBM, On-Chip VMEM): To sustain the MXUs' voracious appetite for data, TPUs employ a carefully designed memory system. This includes High Bandwidth Memory (HBM) for off-chip storage, similar to high-end GPUs.A distinguishing feature is a substantial amount of fast on-chip SRAM, often called Vector Memory (VMEM), which acts as a software-managed scratchpad to stage data from HBM before it's fed into the MXUs.
- Supported Precisions: TPUs are primarily optimized for numerical precisions that balance performance, memory efficiency, and the accuracy needed for deep learning. Bfloat16 (BF16) is a cornerstone, used for multiplications within the MXU, offering the dynamic range of FP32 with half the memory footprint.Accumulations are typically performed in higher-precision FP32 to maintain numerical stability.TPUs also offer strong support for INT8 precision, which dramatically accelerates inference workloads.

- 🟦 Sign bit (1 bit): shown in light blue
- 🟧 Exponent:
- 8 bits for both FP32 and BF16 (shown in orange)
- 🟩 Mantissa (fraction):
- FP32 has 23 bits (more precision)
- BF16 has only 7 bits (less precision)
This highlights the key difference: BF16 retains the same dynamic range as FP32 (due to identical exponent size) but sacrifices precision by reducing the mantissa. This makes BF16 ideal for deep learning where full precision isn’t always needed, especially during training with large matrices.
The Language of AI
Why Matrix Calculations Matter
At the core of nearly every deep learning model, from the simplest perceptron to the most complex LLM, lies a fundamental mathematical operation: matrix multiplication. Understanding its role is key to understanding why GPUs and TPUs are so effective.
Matrix Multiplication: The Unsung Hero
At the core of deep learning is linear algebra, especially matrix multiplication (used in fully connected layers, convolution, attention, etc.).
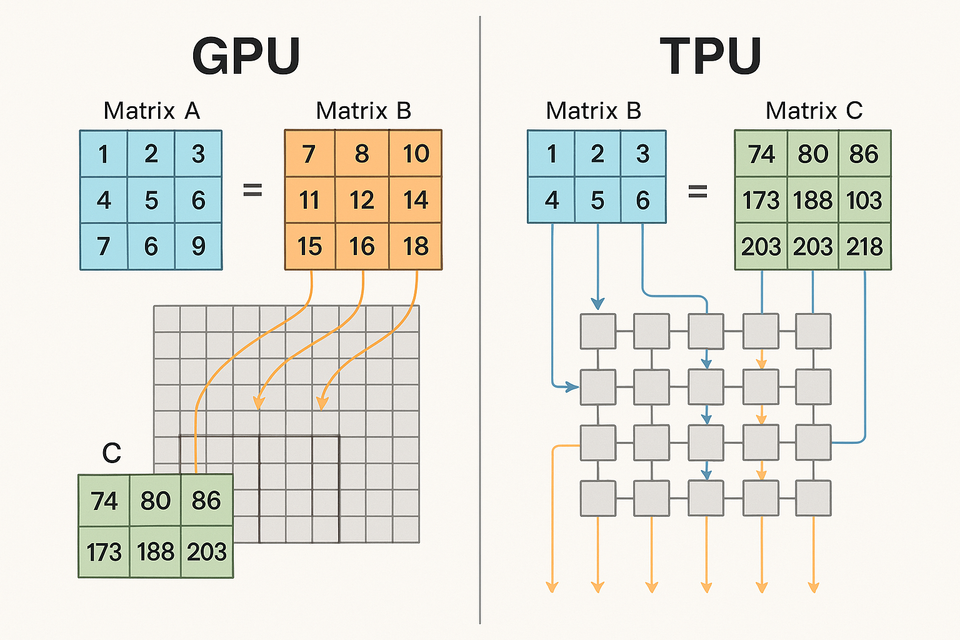
For example, Suppose we have:
- Matrix A: shape (2 × 3)
- Matrix B: shape (3 × 4)
Then, the result matrix C = A × B will be of shape (2 × 4).
Let's expand on this example a bit.
Let:
A = [ [1, 2, 3],
[4, 5, 6] ]
B = [ [7, 8, 9, 10],
[11, 12, 13, 14],
[15, 16, 17, 18] ]
Then the resulting matrix C is:
C = [ [ (1×7 + 2×11 + 3×15), ... ],
[ (4×7 + 5×11 + 6×15), ... ] ]
= [ [ 74, 80, 86, 92 ],
[173, 188, 203, 218] ]

Matrix Math in Neural Networks
This seemingly simple operation is the workhorse of deep learning:
- Feedforward Networks: In a basic feedforward neural network, each neuron in a layer calculates a weighted sum of its inputs from the previous layer.If you represent the inputs as a vector (or a matrix for a batch of inputs) and the connection weights as a matrix, this weighted sum for an entire layer can be computed efficiently with a single matrix multiplication.A bias term is then added, and a non-linear activation function is applied element-wise.

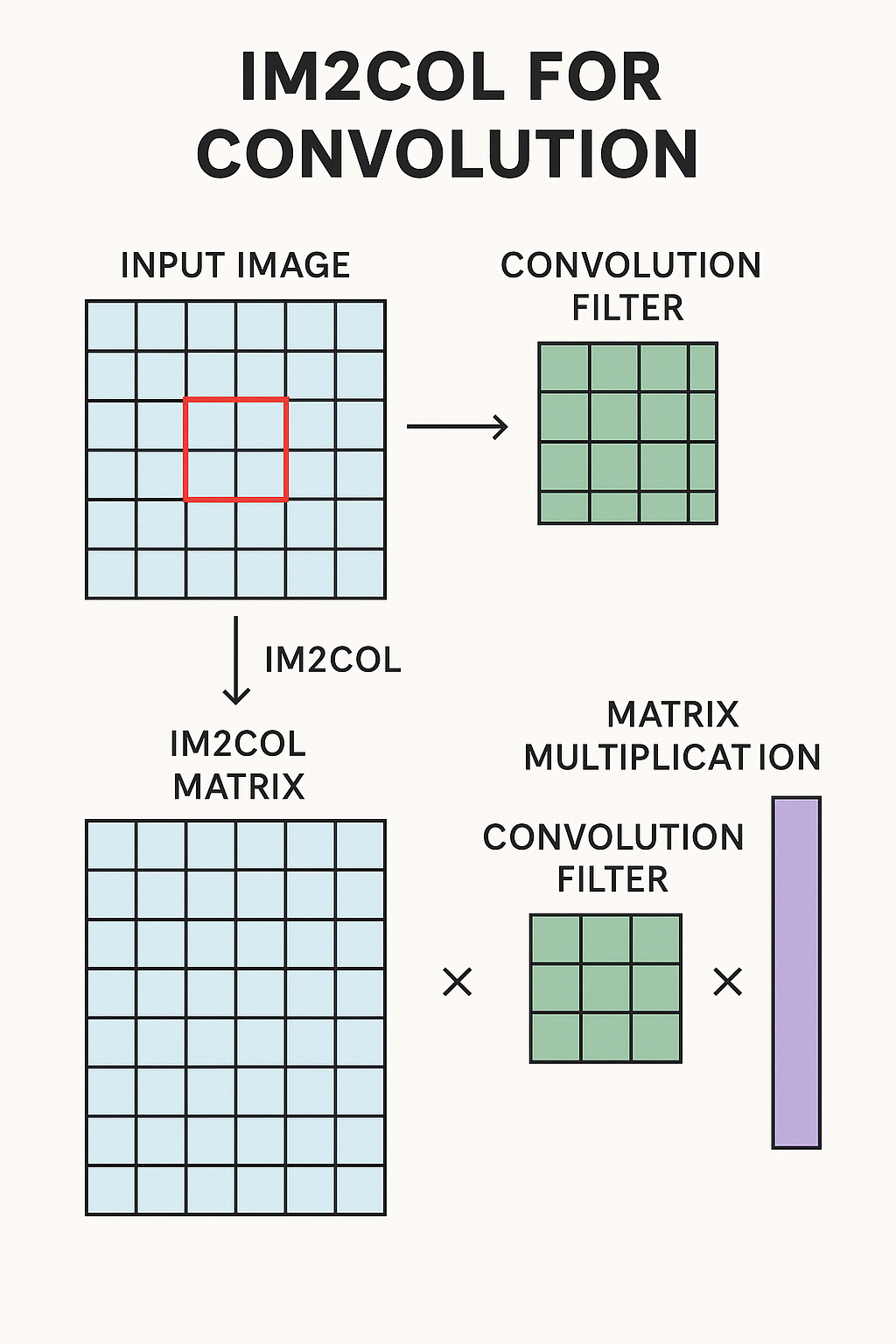
- Convolutional Neural Networks (CNNs): CNNs, the stars of image recognition, use convolution operations where a filter slides across an input image, computing dot products.While not obviously a matrix multiplication, techniques like
im2col(image-to-column) cleverly transform this process.im2colextracts overlapping image patches and flattens them into columns of a large matrix. The convolutional filters are also flattened into rows of another matrix. The convolution then becomes a single, highly optimized matrix multiplication between these two matrices.
- Transformer Models: The self-attention mechanism relies heavily on matrix multiplications to determine how much focus each token in a sequence should place on other tokens. This process involves three key matrices: Query (Q), Key (K), and Value (V), which are generated by multiplying the input embeddings by learned weight matrices (WQ, WK, and WV).
The performance arena
GPUs vs. TPUs Head-to-Head
Now, let's see how these architectural differences play out in the real world of deep learning computations.
Tensor Cores vs. Systolic Arrays
- NVIDIA Tensor Cores: Tensor Cores execute matrix multiply-accumulate (MMA) operations on small, fixed-size tiles of matrices.For example, a third-generation Tensor Core in the Ampere A100 can process an 8×K×8 MMA operation (e.g., an 8×K matrix A, a K×8 matrix B, accumulated with an 8×8 matrix C) per cycle, supporting various precisions like TF32, FP16, and BF16.Data is fetched from the SM's register file or shared memory, and newer architectures like Blackwell introduce "tensor memory" and asynchronous data movement to keep the Tensor Cores continuously fed.Their efficiency comes from specialized datapaths, mixed-precision computation, and features like structured sparsity support.
- Google TPU Systolic Arrays: TPUs employ a weight-stationary dataflow in their systolic arrays.Model weights are pre-loaded into the MAC units. Input activations then stream into the array, and as they propagate, each MAC unit performs its multiplication and adds the result to a partial sum received from an adjacent unit, passing its new partial sum along.Crucially, during this core matrix multiplication, intermediate results are passed directly between MACs without accessing external memory (HBM or even on-chip VMEM), drastically reducing memory bandwidth requirements and power consumption.This design maximizes data reuse and operational intensity.
- Key Differences in Approach:
- Data Handling: GPUs use a more traditional cache/shared memory hierarchy, with CUDA managing data movement. TPUs prioritize keeping data flowing through the systolic array with minimal off-chip access once computation begins, relying heavily on their large on-chip VMEM.
- Parallelism: GPUs combine SIMT parallelism on CUDA cores with the specialized parallelism of Tensor Cores. TPUs leverage massive spatial parallelism within the hardwired systolic array.
- Flexibility vs. Specialization: GPUs are more versatile, handling diverse computations beyond dense matrix math. TPUs are hyper-specialized for dense matrix operations, offering less flexibility for irregular tasks.
Real-World Workloads: Training and Inference
Performance comparisons, including those from MLPerf benchmarks, paint a nuanced picture:
- CNNs: TPUs often show strong performance and high FLOPS utilization, especially for large CNNs and batch sizes, as their architecture aligns well with the dense computations.
- RNNs: TPUs can also achieve high utilization for RNNs if matrix multiplications dominate.However, GPUs might scale better if non-MatMul operations (like large embedding lookups) are significant, due to their flexibility.
- Transformers and LLMs:
- Training: Both platforms are formidable. NVIDIA's H100 GPUs have set records in MLPerf for time-to-train large models like GPT-3.Google's TPU v5e and v5p also show competitive results, often highlighting strong performance-per-dollar at scale.For instance, an 8xH100 system might offer higher raw token generation rates in training than an 8xTPU v5e system, but TPUs can be more cost-effective.
- Inference: TPUs (like v5e and the inference-focused Ironwood) are engineered for high throughput and cost-efficiency at scale, often using techniques like continuous batching.NVIDIA H100 GPUs excel in low-latency scenarios for single-stream or small-batch inference.
It's important to remember that MLPerf results are vendor-submitted and highly optimized for specific configurations, so they represent a snapshot rather than a universal truth. The software stack's maturity also plays a massive role.
Critical Factors: Batch Size, Model Complexity, Energy Efficiency
- Batch Size: TPUs generally thrive on large batch sizes to keep their systolic arrays full and efficient.GPUs, while also benefiting from larger batches, are relatively more efficient with smaller batch sizes due to their flexible scheduling.
- Model Complexity: TPUs excel with models dominated by dense matrix math (e.g., large CNNs).GPUs offer more flexibility for models with mixed operations, irregular patterns, or custom kernels.For extremely large models, model parallelism is key on both platforms, with inter-chip interconnect performance being vital.
- Energy Efficiency: TPUs are generally designed with a strong emphasis on performance-per-watt, often outperforming GPUs in this metric for their target workloads due to their specialized architecture minimizing data movement.For example, TPU v5e is noted to have significantly lower power consumption than an NVIDIA H100 in some comparisons.However, real-world energy use for LLM inference can be much higher than theoretical estimates on both platforms due to underutilization and workload specifics.
The Developer's Toolkit
Software Ecosystems
Hardware is only half the story. The software ecosystem dictates how easily developers can harness this power.
NVIDIA's CUDA Realm
NVIDIA boasts a mature, extensive, and widely adopted software ecosystem centered around CUDA.
- CUDA (Compute Unified Device Architecture): A parallel computing platform and programming model allowing developers to use C, C++, Fortran, and Python to write GPU-accelerated applications.The CUDA Toolkit provides compilers, debuggers, profilers, and libraries.
- cuDNN (CUDA Deep Neural Network library): A GPU-accelerated library with highly optimized implementations of deep learning primitives like convolutions, pooling, and matrix multiplications, specifically tuned for NVIDIA hardware, including Tensor Cores.
- Broad Framework Support & Tools: NVIDIA enjoys deep integration with virtually all major ML frameworks (TensorFlow, PyTorch, JAX, etc.).Specialized libraries like TensorRT (for inference) and RAPIDS (for data science), along with comprehensive profiling tools (Nsight), further enrich the ecosystem.
Google's TPU Universe
Google's TPU ecosystem is primarily built around TensorFlow, JAX, and the XLA compiler.
- TensorFlow: Historically the primary framework for TPUs, offering deep integration and TPU-specific APIs.
- JAX: A high-performance Python library for numerical computing and ML research, increasingly popular for TPUs. It combines a NumPy-like API with powerful function transformations (auto-differentiation, JIT compilation, vectorization, parallelization).
- XLA (Accelerated Linear Algebra): A domain-specific compiler that optimizes numerical computations from frameworks like JAX and TensorFlow into efficient machine code for TPUs (and other hardware).It performs crucial optimizations like operator fusion.
The Experience Factor: Ease of Use, Flexibility, Community
- Ease of Use & Learning Curve: NVIDIA's CUDA ecosystem is generally seen as more mature with extensive documentation and a large community, though direct CUDA C++ can be complex.JAX offers a Pythonic interface favored by many researchers, but debugging and optimizing for TPUs via XLA can sometimes be more challenging, especially for newcomers or with less mature PyTorch/XLA support.
- Flexibility & Framework Support: GPUs with CUDA are highly flexible, supporting nearly all ML frameworks and a wide range of general-purpose parallel tasks.TPUs are primarily optimized for TensorFlow and JAX; PyTorch support via XLA has been improving but sometimes lags.
- Community & Maturity: The CUDA community is vast and mature.The JAX/TPU community is growing rapidly, especially in research, but is generally smaller and more Google-centric.
NVIDIA's "software moat" with CUDA is significant.However, Google's compiler-centric approach with JAX/XLA aims for high performance through abstraction and optimization, appealing particularly to researchers.The choice of framework can heavily influence performance on each platform.
The ever-evolving AI hardware frontier
| Aspect | GPU | TPU |
|---|---|---|
| General Use | Flexible, broad ML/DL use cases | Specialized for deep learning |
| Matrix Op Speed | Very high (Tensor Cores) | Extreme (systolic arrays) |
| Precision Support | FP32, FP16, BF16, INT8 | BF16, INT8, FP32 |
| Hardware Access | Widely available (consumer & cloud) | Google Cloud (TPU via Colab, GCP) |
| Developer Ecosystem | Large, robust (multi-framework) | Primarily TensorFlow, emerging JAX support |
| Ideal Workloads | Broad (vision, NLP, RL) | Large-scale training/inference, LLMs |
Choosing between GPUs and TPUs isn't about finding a universally "better" option. It's about understanding their distinct strengths, architectural philosophies, and software ecosystems, and then matching those to the specific demands of your deep learning projects.
GPUs offer incredible versatility, raw power, and a mature, expansive software environment, making them a default choice for many. TPUs, with their laser focus on AI-specific matrix math, provide compelling efficiency and performance for targeted workloads, especially at scale within the Google ecosystem.
The "best" accelerator today might be superseded tomorrow as new architectures and software innovations emerge. The key is to continuously evaluate your needs against the evolving capabilities of these remarkable pieces of technology. The journey into AI-accelerated computing is a dynamic one, and the right hardware choice can be the critical enabler for your next breakthrough.